Self Hosting an MLOps Platform IV

Alvaro Gallego
Apr 07, 2022
After having deployed ArgoCD in our cluster, we can sync from git our apps to kubernetes. In a production environment, we'd need to run some tests, build our app, create and push the image to our container registry and update the deployment manifests. A good practice is to keep all the deployment in separate branches and make the release from the main or master branch to later deploy on kubernetes.
The building process usually starts first with defining the testing environment, can be a simple virtual image with some sdk in it, eg. python image or jdk, preferably multiarch based, in a pipeline after making changes in the main branch. For instance setting up docker buildx and qemu for testing and building our image artifacts, and if tests are passed, then push to a registry. Probably we'd setup this in CI/CD integrations from our git eg. github actions or gitlab pipelines.

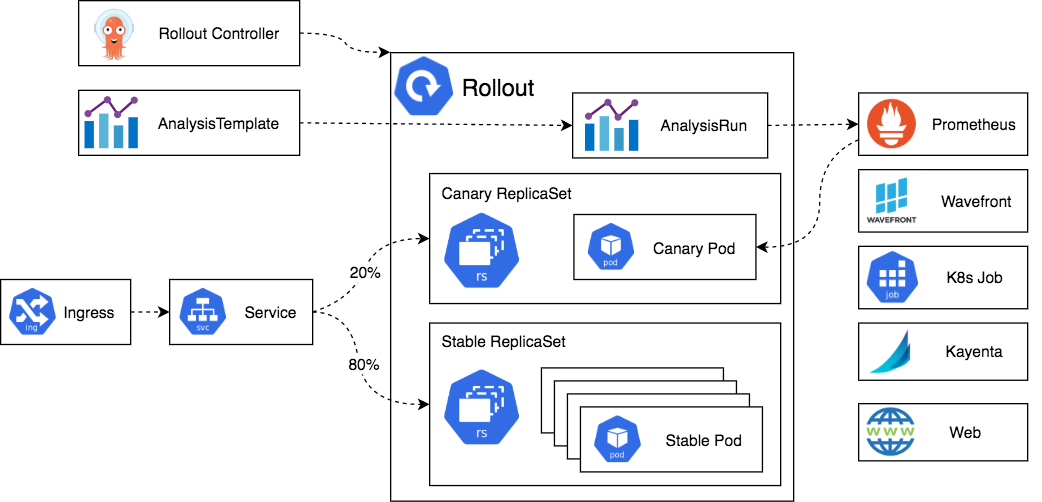
This CI/CD integrations usually contain a list of stages, and each stage contains tasks or jobs. These jobs are triggered by some predefined event that can be scheduled, manually triggered or a git related event like merging a pull request. This can help a lot with our SRE scenario, though we probably want to manage many releases and split traffic between them to see how our users respond to new changes in our app, and probably pick some candidate version as final.
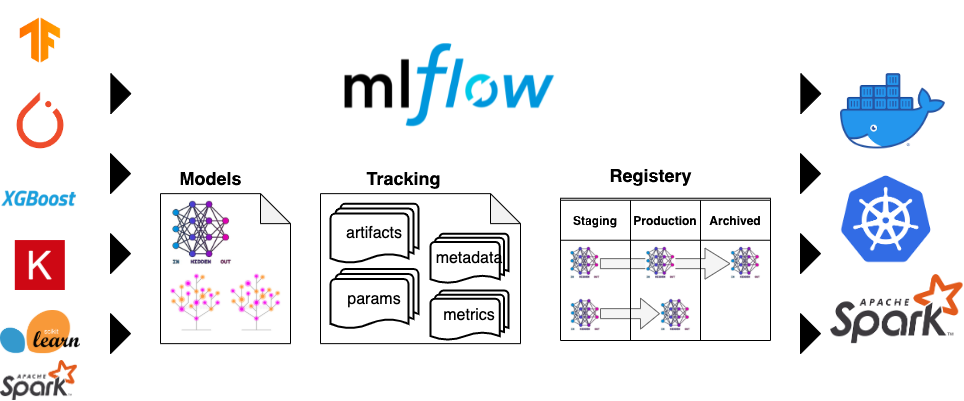
So this is where the rest of Argo products come in, Argo Workflows, Argo Rollouts and Argo Events.
Argo workflows could be used create some stress testing, Argo Rollouts could analyze the deployments and Argo events notify to our messaging system and trigger another workflow to add new changes.
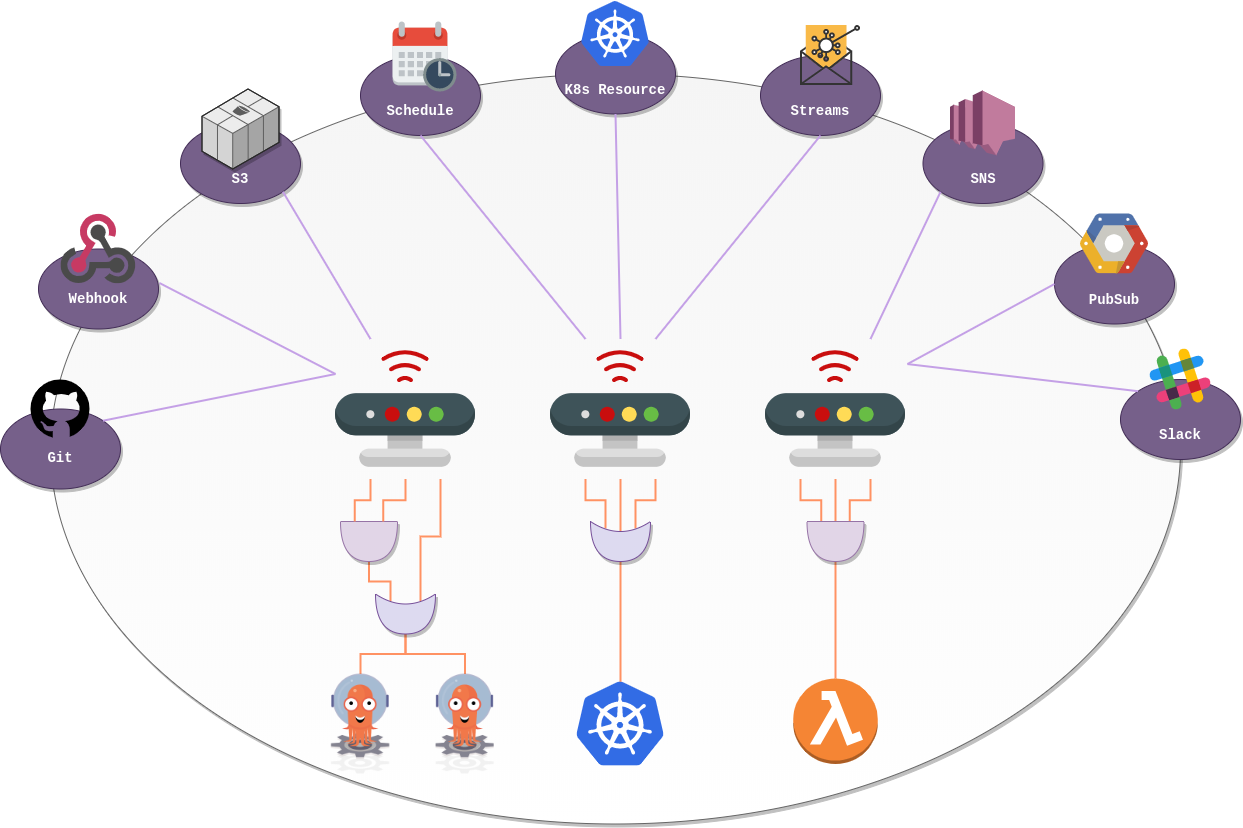
Mind that all the build process could also run within Argo, by creating a git webhook in our git provider So all testing and building process could run in our cluster. This can be relevant if we own different machines with different architectures. Or when looking for performance, where software needs to be tested natively, as virtualizing with qemu for multiple architectures increases build time and have a negative impact on final performance.
Now, what if rather than building and deploying our app based on our tests, we are interested in building and deploy a machine learning model if metrics improve?
In computing, a pipeline, also known as data pipeline, is a set of data processing elements connected in series, where the output of one element is the input of the next one. The elements of a pipeline are often executed in parallel or in time-sliced fashion. Some amount of buffer storage is often inserted between elements.
In Machine Learning Model Operationalization (MLOps), we pursue a way to provide end-to-end machine learning development process to dessign, build, and manage reproducible, testeable and evolvable ML-powered software.
The main difference between DevOps and MLOps is that our git (version control system) should be replace by a model server, and this model server should track and serve our models, be able to scale, store the models, and its hyper-parameters, so it can be reproducible.
So, though MLOps and DevOps share the same philosophy, they are not the same. But that would cover another blog.
Tags